Fundamentals
Introduction
GCP offers four main services:
- Compute
- Storage
- Big data
- Machine learning
The fundamentals course covers mainly the first two plus networking.
Cloud computing is an on-demand infrastrucuture available under the following characteristics:
- Compute resouces on-demand self-service: no human intervention
- Access from anywhere in the internet
- Resource pooling: GCP provides share-base resources
- Rapid elasiticity: Get more resources quickly as needed
- Measured service: pay for what you consume or use
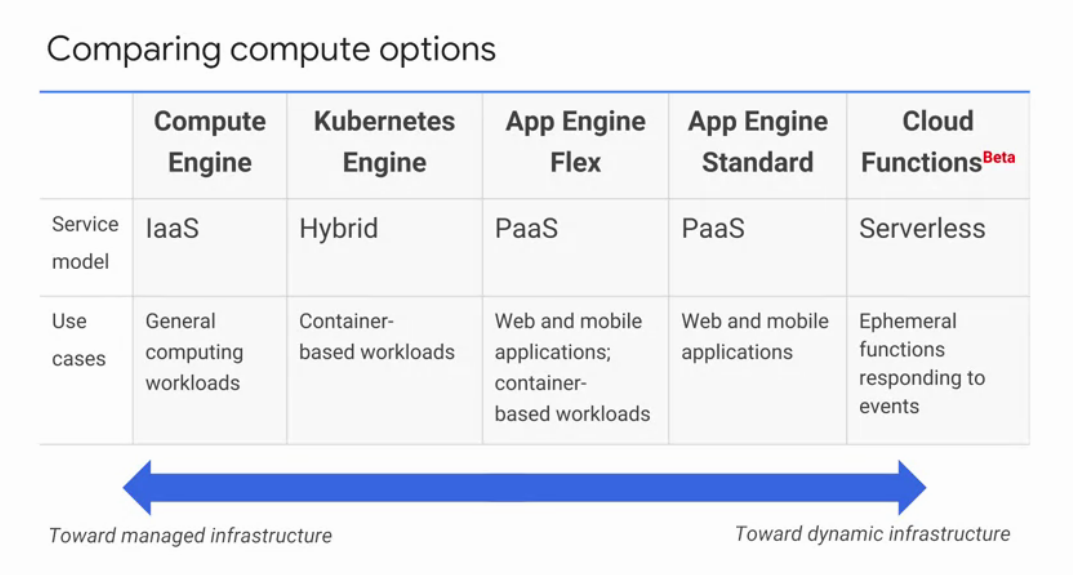
There are serveral GCP computing services, such as:
- IaaS: where you pay for what you allocated
- PaaS: where you pay for what you use
GCP allocation:
- Zone: Deploymenat area, not geographically related. A zone is a single failure domain witdh in a region.
- Region: Group of zone, independen geographical areas.
The basics
To work in GCP you organise your work load in projects. These projects organize GCP resorues with common basic objectives. Access to GCP is through IAM, GCP ID and Access Management, and it defifnes who can do what.
User interfaces to access and interact with GCP includes:
- Web interface ( GCP console and generally used at the begining )
- SDK ( gcloud, gsutil for cloud storage, bq for Big query )
- Command line ( cloud shell )
- RESTful API ( uses JSON and OAuth 2.0 authentication and authorization )
- Mobile App
All resources in GCP are organised into projects.Optionally, this projects can be organised into folder and subfolders. All these projects, folders and subfolders that belongs to an organisation can be brought under an organisation node. Each project is separated compartiment and usually have the following id:
- Project ID: Global inmutable unique name chosen by you.
- Project name: Can be mutable and chosen by you.
- Project number: Global inmutable number given by GCP.
On the other hand, a policy is set on a resource, where each policy contains a set of roles and role members. Resources inherit policies from parents, where a less restrictive policy overrides a more restrictive resource policy. For example, if a organisation node policy is set to read only, but a project policy is set to read and write, then read and write is possible for that project. Take in mind this when you design your policies.
The Identity and Access Management, IAM, helps to manage access rights to currents users of a project. There are three parts:
- Who: Identifies the user or resource, such as google or service account, group, domain.
- How/when: This uses AIM Role, a collection of permissions: primitive, predefined, and custom.
- Primitive are broad an include: owner, editor , viewer and billing administrator.
- Predefined: Pre designed rules that can be used.
- Custom: Where you design and set your own roles.
- What: GCP Resource.
Note to give access permissions to a VM you need to use a service account.
GCP Launcher is a quick tool for deployment that contains a pre-packaged and ready-to-deploy solutions. Some of these solutions are offered by Google and others by third-party vendors. GCP upgrades on the VMs do not update installed packages, but GCP allows you to maintain them.
Virtual Private Cloud (VCP) network
VCP is a set of one or many virtual machines interconnected through a virtual network inside your project in GCP. It is similar to a traditional network where you can define your own firewall rules to restrict access to internal resources or create static routes to redirect traffic to specific destination. An important feature of VCP in GCP is its global scope, which allow your virtual machines to be reachable globaly. It is possible to allocate resources in different zones or expand resources, such as storage or network, to any virtual machine inside your VCP. One tip at this stage is to use preemptible VMs which allows you in some extend to reduce costs.
A VM can be creatd by console UI or by command line, gcloud. If there is not a pre-define image of your interest, you can customise your own image. Additionally, in cases such as intensive data analysis, you can use a local SSD disk. However, you need to store the data of permanent value in different place as GCP will not leave data on your local SSD disk after all process has finished. For this last case, you can use GCP persistent disks.
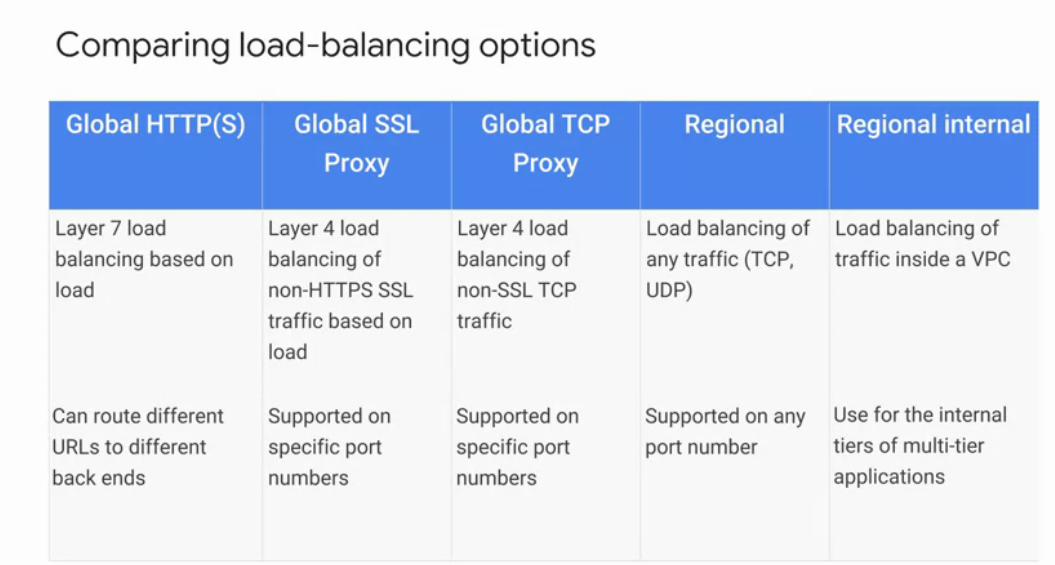
At booting time, you can als provide to GCP start-up scripts or metadata to initialise your VM. It is possible to define the number of CPUs and memory size for each VM, for example, at the time of this writing, the maximum number of CPU to provision was 96, and the maximum memory size in data was 624 GB. To complete tasks such as intensive data analytics, GCP offers auto-scale, which automatically deploys new VMs base on the load of your task. Additionally, GCP offers cloud load balancing base on the incoming traffic. The options that GCP offer for cross regional load balancing are:
- Global HTTP(s): Layer 7 load balancing based on load. It routes different URLs to different backends.
- Global SSL proxy: Layer 4 load balancing for non-HTTPS SSL traffic.
- Global TCP proxy: Layer 4 load balancing of non-SSL TCP traffic.
- Regional: Load balancing of any traffic, TCP and UDP on any port.
- Regional internal: Load balancing of traffic inside a VPC. All options have this option.
Inside a VCP, GCP already set up a firewall and routers, you do not need to provision these resources manually. However, you can configurate them as you need. This feature comes automatically because VCP networks belong to GCP projects. In case you need to allow communication between two VCP from different GCP project, you can use VCP peering. Additonally, you can difine access rules between VCPs using VCP sharing, which define who and what can be accessed from one VCP to another.
On the other hand, GCP offers also Cloud DNS, which can be manage programatically through its API or by command line. You can manage zones, which includes edit, add, remove DNS entries. Finally, Cloud CDN is able to cache your content close to your clients.
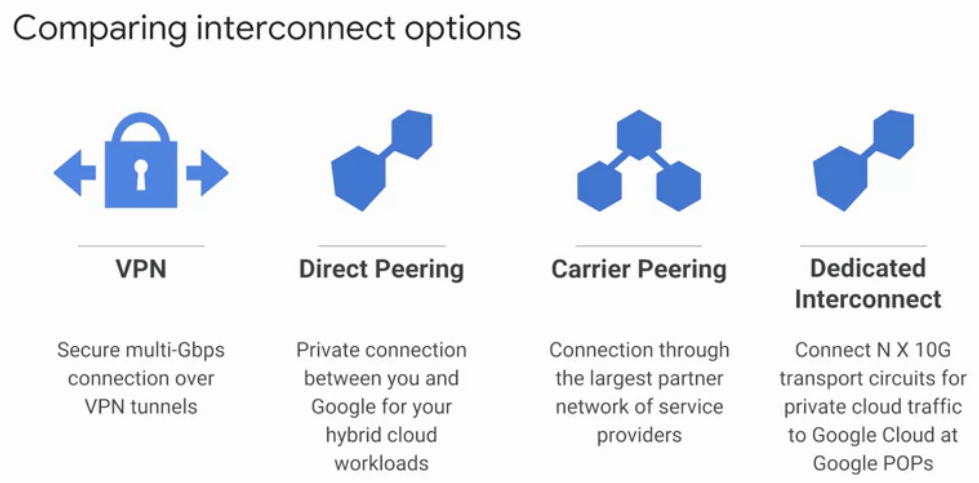
Note that in the case you want to interconnect with external networks or your own local network, GCP offers the following options:
- VPN: Through a cloud router using Boarder Gateway protocol. This means you access your GCP through internet.
- Direct peering: This is private connection between your network and GCP. This is not cover GCP SLA.
- Carried peering: Connection through the largest partner network of service providers.
- Dedicated Interconnect: Connects nx10G transport circuit for private cloud traffic.
How to create a VM using UI console
1. Login to GCP console --> Click product and services --> Compute Engine --> VM instances --> create.
2. Edit name, zone, VM specs as you need --> Click create.
How to create a VM by command line
1. Click on Activate Google Cloud shell ( icon on the top bar )
2. $gcloud compute zones list # List all available zones
3. $gcloud config set compute/zone us-central1-c # Sets the zone
4. $gcloud compute instances create "MYVM" \
--machine-type "n1-standard-1" \
--image-project "debian-cloud" \
--image "debian-9-stretch-v20170918" \
--subnet "default"
Basic inspection
- You can ssh into your VM by click on the SSH in the console interface.
- You can ssh from one VM to another by ssh <NAME_VM> directly.
- You can install a web server, such as nginx-light, and use http to retrieve content.
- Use sudo to have admin privileges without a password.
Storage
You can store data inside the VMs you ship in GCP. However, GCP can store structured, unstructured, transactional and relational data throught the following services:
- Cloud storage
- CLoud SQL
- Cloud Spanner
- Cloud Data Store
- Google Big Table
Cloud storage Cloud storage uses object storages to store your data. Object storage is not same as the traditional file storage or block storage. Instead, the whole object is stored by associating it to a key, a key that has a URL form.
Cloud storage is a set of buckets, that are inmutable, which means that you can not edit them, but you can create a new version of them. Cloud storage always encrypt your data in the server side.
Each bucket has a unique id and location. You can move one bucket from one location to another in order to optimise latency. To control access to your buckets you can use Cloud IAM, which in general is sufficient. Each of the access control lists, ACLs, have two parts: one to specify the user or group of users and the other to specify the type of permissions associated to these users or groups.
Additionaly, you can turn on versioninng, which allows you track all modifcations of you object storage. However, if you turn off your versioning, you will always have one version of your object storage, which means that the old version will be replaced by the new one.
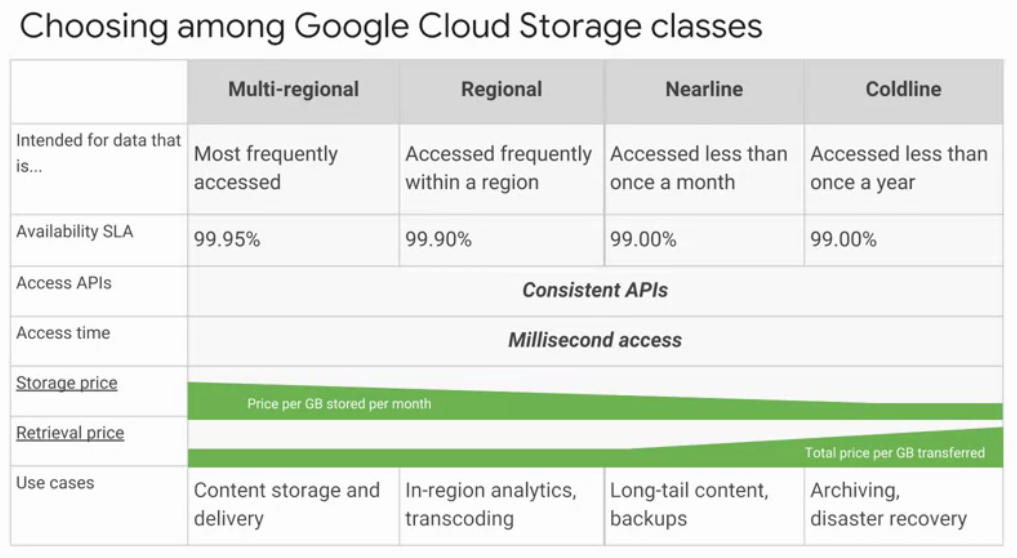
GCP offers four Cloud storage classes:
- Regional(99.95% availability): Let your store your data in a specific region. Cheaper but less redundant. Examples include: Europe west, asia east.
- Multi-regional(99.90% availability): Stores your date in a at least two geographica regions separated by at lease 160 km. Examples include: EU, Asia. Ideal for data frequently accessed.
- Nearline(99.00% availability): It is a low cost and ideal for unfrequently accessed data, such as once a month or lest on average.
- Coldline(99.00% availability): It is a very low cost and ideal for data accessed less than once a year, such as archiving, online backups and disaster recovery.
There are several methods to transfer your data into Cloud storage. These methods include gs-util, drag and drop, online transfer storage service and the offline transfer appicanes tools. Cloud Storage also works with other GCP services to transfer your data, these services include import export tables using BigQuery and cloud SQL, Object storage, logs and backups from App engines, scripts and images from Compute Engine.
Google Big Table
It is a NOSQL Big Data database service. Bigtable can scale to billonw of rows and thousands of columns allowing you to store petabytes of data. It is ideal for storing large set of data with low latency, it support high throughput to both read and write, which make it a good choice for operational and analytical analysis.
It uses the same open source API as HBase. The advantages of using Bigtable over Hbase are:
- Scalability: especially when query rates per time increases, GCP manages to scale up your cluster through a machine counter.
- Administration: These tasks are transparent to the user, and GCP manages all operational work such as updates, and patches.
- Encryption: Data is encrypted in both in-flight and at rest. Also IAM permissions can be applied to RBAC to Bigtable data.
- GCP: Bigtable is same data base used by Google's core services such as search, analytics and maps.
Bigtable can be accessed by the following patterns:
- App API: You can write and read from Bigtable using service layer like VMs, HBase REST server or Java server through HBase client.
- Streaming: You can use popular tools such as Cloud Dataflow, Spark Streaming and Storm.
- Batches: You can read and write using Hadoop Mapreduce, Dataflow, or Spark.
CLoud SQL
This is a RDBMS service. Offers MySQL or PostgreSQL databases as service. The benefits of using Cloud SQL rather than set my own database in the cloud, is that Cloud SQL offers:
- Automatic replication: read, failover and external replicas. This means that Cloud SQL can replicate data within multiple zones without failover.
- Backups: Cloud SQL offers you backup your data on-demand or base on schedules. The backup could be vertical, by changing the machine type, or horizontal via read replicas.
- Security: Cloud SQL includes network firewalls, customer data encryption when data is in internal Google's networks.
- Visibility: Cloud SQL instances are accessible by other GCP or external services.
Cloud SQL can be used with App Engine application. Compute engine instances can be authorized to access Cloud SQL using external IP address and also can be configured with a preferred zone. Additionaly, Cloud SQL can be adminnistrated by external tools or can be set external replicas.
Cloud Spanner
Cloud Spanner offers an horizontal scalability for Cloud SQL. It offers transactional consistency at global scale, schemas , SQL and automatic synchronous replication for high availability. Cloud Spinner can be consider when you have an outgrown any relational database or you need glocal data transactional consistency such as the cases of financial application and inventory applications.
Cloud DataStore
It is another high scalable NOSQL database service. Its main case is to store structured data from App Engine applications. Cloud DataStore automaticaly handles replications and sharding.
Summary
The following figures present a summary of technical differences between GCP services and their common use cases.
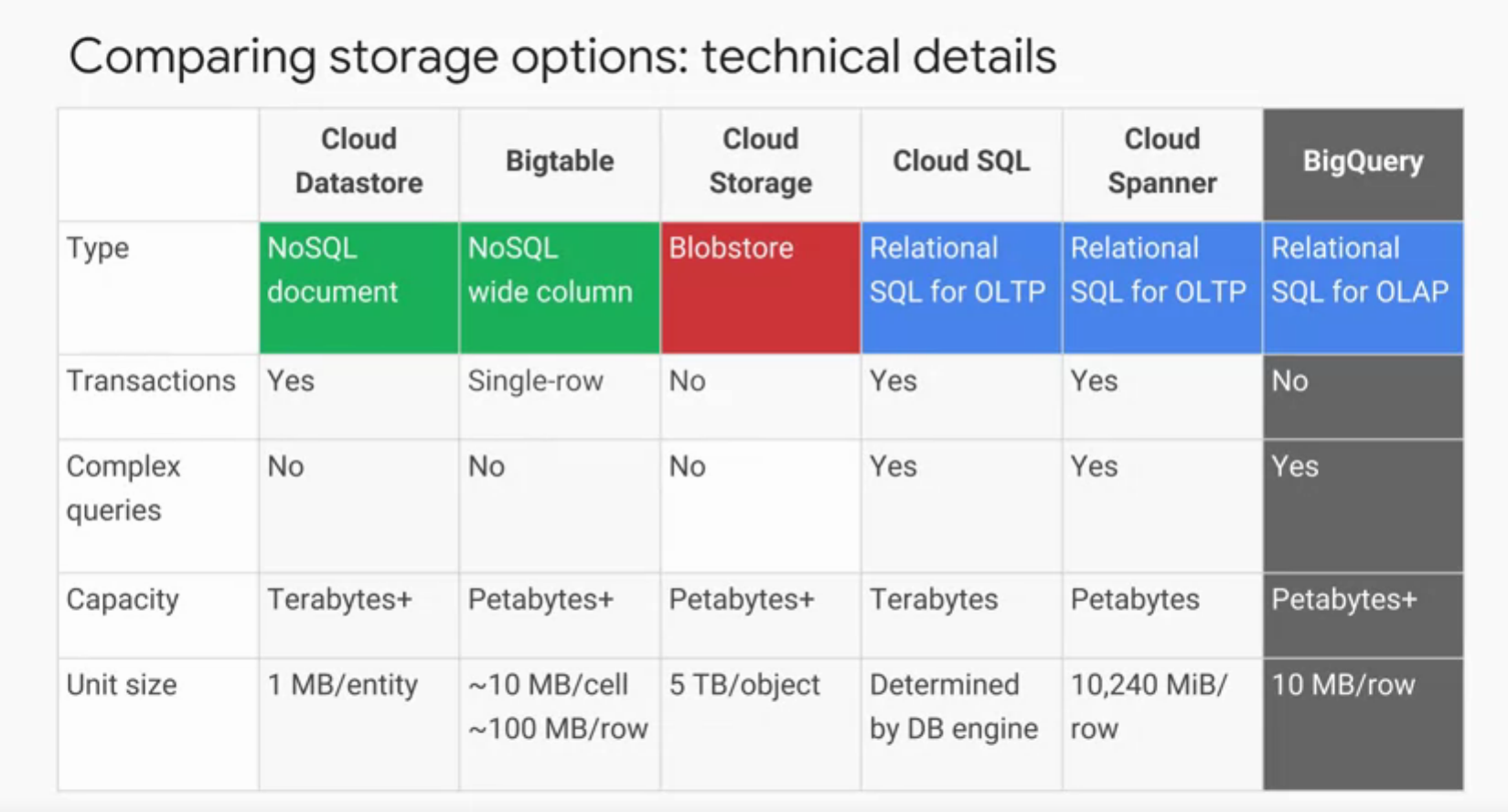

Note: These figures are screenshots took during the course. Credits to GCP training material
How to get started with Cloud Storage and Cloud SQL
- Create a VM with an Apache web server and upload an image to a new bucket.
- Create a VM as it was described on section "how to create a VM ...".
Before click create please add a start up script that install a web server in this VM by expanding the link "management, disks, networking, SSH keys" and look for the "Startup script". You can copy the following:
apt update
apt isntall apache2 php php-mysql -y
service apache2 restart
- Create a bucket and upload any image to this bucket.
You can click on cloud shell and type:
$ gsutil mb -l EU gs://$DEVSHELL_PROJECT_ID # This creates a bucket with an UNIQUE ID,my google project id
$ gsutil cp gs://cloud-training/gcpfxi/my-excellent-blog.png my-image-blog.png # Copy an image to my local VM
$ ls # This should show that the images is in your VM now.
$ gsutil cp my-image-blog.png gs://$DEVSHELL_PROJECT_ID/my-image-blog.png # This uploads my image to my bucket.
$ gsutil acl ch -u allUsers:R gs://$DEVSHELL_PROJECT_ID/my-excellent-blog.png # modify access permissions
$ gsutil ls gs://$DEVSHELL_PROJECT_ID # will show you the content of your bucket, not VM.
Also you can see open your bucket using the GUI and see if it is there. To do so, click on Storage -> Browser -> Click on the name of the bucket. In here check the box for "Share plublicly". Please, copy the link somewehre we will use it to point from the index.php page of this webserver.
- Create SQL instance
- Click on Products and Services -> Storage -> SQL - > Create Instance -> MySQL
- Give a name of this instance and set a password. Remember to choose the same ZONE as the VM on step 1. Click create.
- Click on the name and create an account: click on users -> create users -> type user name and password -> Click create.
- Restrict the access to this SQL instance to VM on point 1. Click authorization -> add network -> Give a name -> Copy the publick IP address of the VM on point 1. Remember add /32 as mask for the public IP address, this is to protect from broad internet access.
- Configure your Apache main page
- Login to the VM created on point 1 using SSH.
- Edit the /var/www/html/index.php and add php code to connect to the DB of point 2 and show the image uploaded in point 1.
- Restart Apache and open in a browser "public ip address of VM"/index.php. You should be able to see the image we uploaded on point 1 and see a connection succed message to the SQL instance.
As a quick example here some tips:
html>
<head><title>Welcome to my excellent blog</title></head>
<img src='https://storage.googleapis.com/qwiklabs-gcp-0005e186fa559a09/my-excellent-blog.png'>
<body>
<h1>Welcome to my excellent blog</h1>
<?php
$dbserver = "CLOUDSQLIP";
$dbuser = "blogdbuser";
$dbpassword = "DBPASSWORD";
// In a production blog, we would not store the MySQL
// password in the document root. Instead, we would store it in a
// configuration file elsewhere on the web server VM instance.
$conn = new mysqli($dbserver, $dbuser, $dbpassword);
if (mysqli_connect_error()) {
echo ("Database connection failed: " . mysqli_connect_error());
} else {
echo ("Database connection succeeded.");
}
?>
</body></html>
Containers in the Cloud
You can build container images though tools such as docker or cloud build. However, more tasks are needed to have a reliable and scalable system, therefore more considerations are needed, such as: service discovery, application configuration, managing updates and monitoring.
- Introduction to GKE
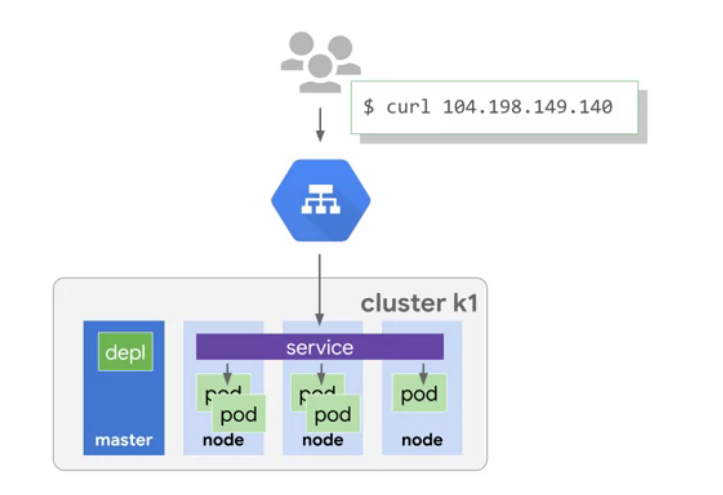
Kubernetes is an open source orchestrator for containers, it helps to manage and scale your containers. Kubernetes lets you deploy containers inside nodes called cluster, where a cluster is a set of master nodes and containter nodes. In kubernetes, a node is a computing instance, in contrast, in GCP, a node is a VM running inside a compute engine.
To create a Kubernetes cluster in GKE, you can type the following command. Note that Kubernetes create “pods” to locate one or more than one containers of a Kubernetes cluster, which means a container runs inside a pod.
``bash $ gcloud container clusters create k1 # This creates a Kubernetes cluster called k1
Here some useful basic commands:
```bash
$ kubectl run nginx --image=nginx:1.15.16
$ kubectl get pods
$ kubectl expose deployments nginx --port=80 --type=LoadBalancer # creates public IP to be accessed by public
Note that by exposing to the public, GKE creates a service that uses a public IP address. This service is the end point for any request from outside, and is this service that re-directs any outside request to the respective pod. The advantage to use service IP address instead of the pod’s IP address is that pods need manages in the case IP addresses change, whereasa service do the manage for you.
$ kubectl scale services
In case you need more resources, you can scale your infrastructure by:
$ kubectl scale nginx --replica=3
$ kubectl autoscale nginx --min=10 --max=15 --cpu=80
$ kubectl get pods -l "app=nginx" -o yaml # declarative eay to use yaml file for configuration.
$ kubectl get replicasets # replicas states
$ kubectl get pods
$ kubectl get deployments # To verify that replicas are running
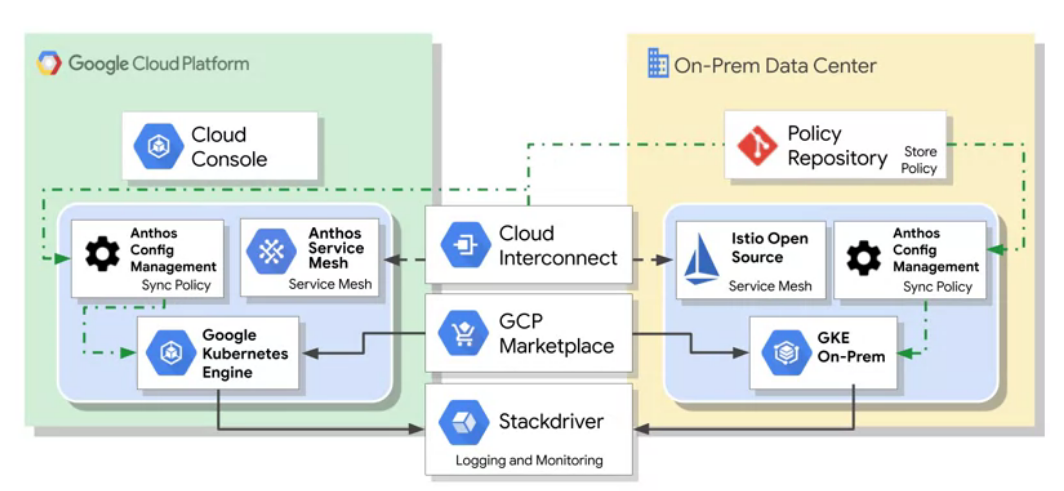
- Hybrid and multi-cloud computing: Anthos
Anthos allows you to move some components of your on-premises application to the cloud, while keeping the rest on your own local infrastrcuture. Anthos allows both, cloud and on-prem, stay in sync, and offers a rich set of tools to manage services on-prem and on cloud, monitoring, migrations of apps from VMs int your clusters, and maintain policies across all clusters.
Applications in the Cloud
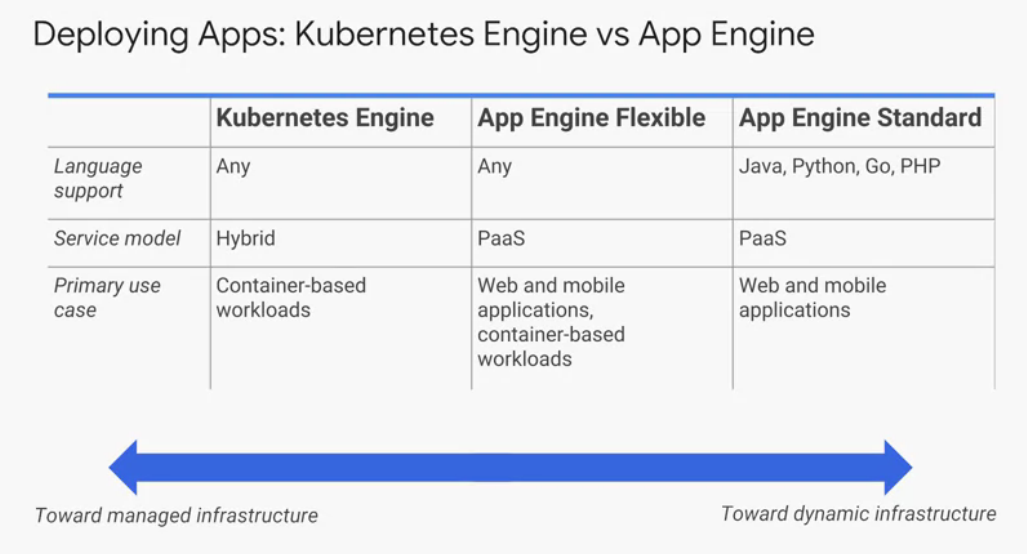
- App Engine: PaaS
This could be useful when you want to focus effort on implement your code rather than in the platform where you deploy your application. App engine is a better solution for a web app rather than a longer-running batch processing. Beside run your application, App engines offers other services to your application, such ash NoSQL databases, load balancing, loggin and authetication.
- The App Standard Engine
Run times services includes: java, python, php, and go. If you code in anothe language, Standard environment is not the rigth place, instead you can choose the flexible environment. In standard environment you use sandboxes, which no writes in local files, if you need data persistance, you can write down to a data service instead. Also all request time out at 60s, and has a limit of thrid-party software.
- The App Engine Flexible environment
You deploy your application inside containers, and GCP manage them for you.

- Could Endpoints and Apigee Edge
Cloud endpints helps you to create and mantain APIs, distribute API managemente through a console and expose your API using RESTfil interface. Apigee also helps you secure and monetize APIs. Apigee contains analytics, monetization and a developer portal. It is usually used by business developers when they want to expose legacy code though APIs to another business customers. Instead of replacing the monoitic application all in once, it peal layer by layer or component by component until complete all migration. It usually implementes microservices to expose APIs until the legacy code can be retired.
- Notes
- App Engine manages the hardware and networking infrastructure required to run your code.
- It is possible for and App Engine application’s daily billing to drop to zero.
- Three advatnages for App Engine Standard: scaling is finer-grained, billing can drop to zero if your application is idle, and GCP provides and maintain runtime binaries.
- In case you want to do business analytics and billing on a customer-facing API, Apigee Edge is a good choice.
- In case you want to support developers who are building services in GCP through API logging and monitoring, Cloud Endpoints is good choice.
- Below some gcloud command to deploy an app in App Engine:
To run the app, not deploy it yet:
$ gcloud auth list
$ gcloud config list project
$ gcloud components install app-engine-python
$ gcloud app create --project=$DEVSHELL_PROJECT_ID
$ git clone https://github.com/GoogleCloudPlatform/python-docs-samples
$ cd python-docs-samples/appengine/standard_python37/hello_world
$ sudo apt-get install virtualenv
$ source venv/bin/activate
$ pip install -r requirements.txt
$ python main.py
To run and deploy the app:
$ cd python-docs-samples/appengine/standard_python37/hello_world
$ gcloud app deploy
$ gcloud app browse
Developing, Deploying and Monitoring in the Cloud
- Development
- GCP includes a cloud source repository, it provides a git for development. It also includes a source viewer.
- Payments is in intervals of 100 milliseconds.
- GCP allows you to create triggers to update new events in your application.
- Infrastrcuture as a code
- GCP provides you a deployment manager for re-deployment by usign a .yaml template file.
- This .yaml template file describes your environment which are read by deployment manager.
- Deployment manager create the resources declared in the .yaml file.
- Monitoring
- GCP uses stackdriver for monitoring, logging, debug, error reporting, and trace.
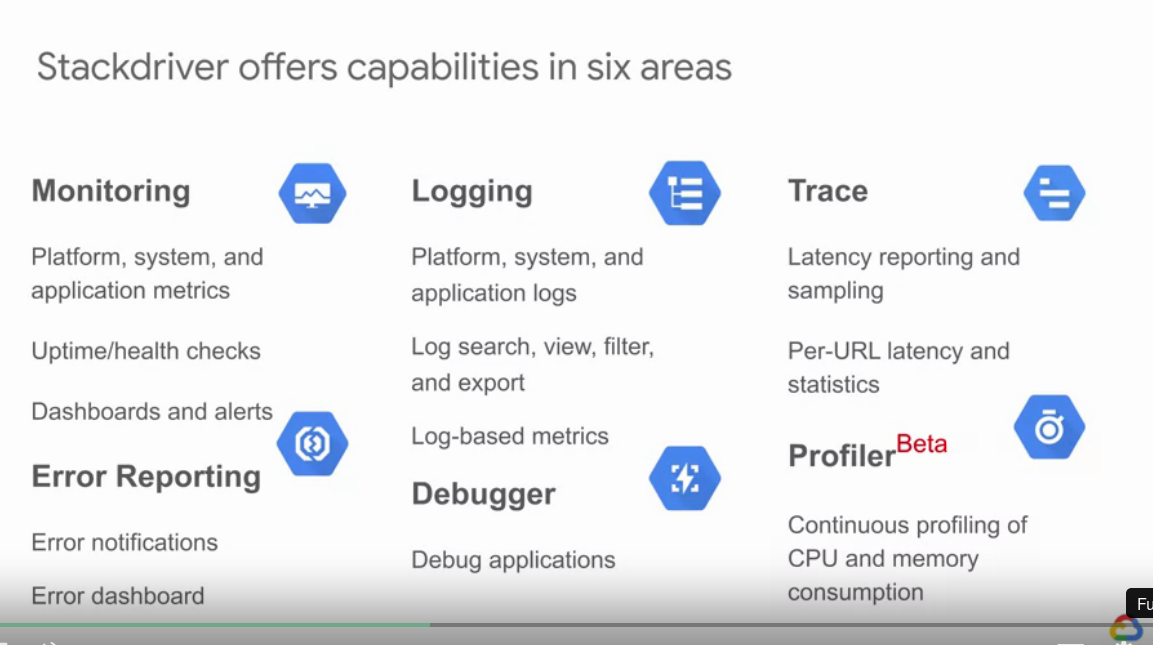
- Notes
- Example of a yaml file to deploy a box in GCP.
$ export MY_ZONE=us-central1-a
$ gsutil cp gs://cloud-training/gcpfcoreinfra/mydeploy.yaml test.yaml
$ sed -i -e 's/PROJECT_ID/'$DEVSHELL_PROJECT_ID/ test.yaml
$ sed -i -e 's/ZONE/'$MY_ZONE/ test.yaml
$ cat test.yaml
resources:
- name: my-vm
type: compute.v1.instance
properties:
zone: us-central1-a
machineType: zones/ZONE/machineTypes/n1-standard-1
metadata:
items:
- key: startup-script
value: "apt-get update"
disks:
- deviceName: boot
type: PERSISTENT
boot: true
autoDelete: true
initializeParams:
sourceImage: https://www.googleapis.com/compute/v1/projects/debian-cloud/global/images/debian-9-stretch-v20180806
networkInterfaces:
- network: https://www.googleapis.com/compute/v1/projects/$DEVSHELL_PROJECT_ID/global/networks/defaul
accessConfigs:
- name: External NAT
type: ONE_TO_ONE_NAT
$ gcloud deployment-manager deployments create HalloWOrld --config test.yaml
# To update VM in caste test.yaml files is modified:
$ gcloud deployment-manager deployments update HalloWOrld --config test.yaml
- To create CPU Load
$ dd if=/dev/urandom | gzip -9 >> /dev/null &
Big Data and Machine Learning in the Cloud
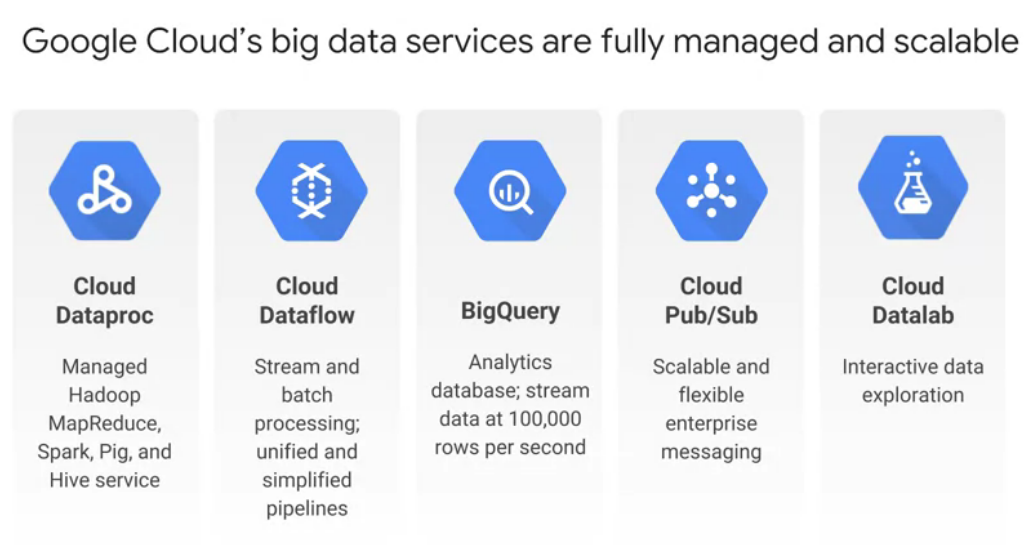
-
MLlib is to run classification algorithms. - TensorFlow - Used for classification, regresion, recommendation, anomaly detection, image and bideo analysis and text analytics.
-
Cloud Dataflow: - Manage data pipelines - “write code once and get batch and streaming” - ETL (extract, transform, load) pipelines to move, filter, enrich, shate data - Data analysis usgin streaming
-
BIg query: - Fully managed data warehouse - Provides near real-time interactive analysis of peta-bytes of datasets using SQL 2011 syntax - Computes with a terabit network
-
Data Pub/Sub - Supports many-to-many async messaging - Apps components make push/pull subscriptions to topics
-
Cloud datalab - Interactive data exploration for large-scale data exploration, transformation, analysis, and visualization - Built on Jupyter(Ipython) - Integration with BigQuery, Compute Engine and Cloud Storage using Python, SQL, and JS
-
Cloud vision - Analyse content of images with REST API - Logo detection - Label detection - Extract text
-
Cloud NLP - Return text from audio in real time - High accuracity, even with noise - It can do syntax analysis - Breaking down sentences supplied by our users into tokens - Identify the nouns, verbs, adjectives, and other parts of speech and figure out the relationships among the words
-
Cloud translation API - Translate arbitrary string in to another language
-
Cloud video intelligence API - Annotate content of videos - Detect sceme changes - Flag inappropiate events
Summary